Other HA Techniques That Yield Great Results
Microsoft has been
revisiting (and architecting) several operations that previously
required a table or whole database to be offline. For several critical
database operations (such as recovery operations, restores, indexing,
and others), Microsoft has either made the data in the database
available earlier in the execution of the operation or made the data in
the database completely available simultaneously with the operation. The
following primary areas are now addressed:
Fast recovery—
This faster recovery option directly improves the availability of SQL
Server databases. Administrators can reconnect to a recovering database
after the transaction log has been rolled forward (and before the
rollback processing has finished). Figure 1 illustrates how Microsoft makes a SQL Server 2008 database available earlier than would SQL Server 2000.
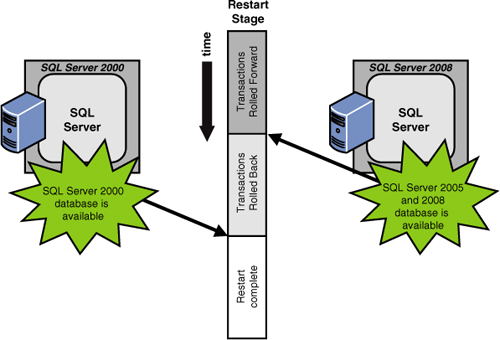
In particular, a
database in SQL Server 2008 becomes available when committed transaction
log entries are rolled forward (termed redo) and no longer have to wait for the “in flight” transactions to be rolled back (termed undo).
Online restore—
Database administrators can perform a restore operation while the
database is still online. Online restore improves the availability of
SQL Server because only the data being restored is unavailable; the rest
of the database remains online and available to users. In addition, the
granularity of the restore has changed to be at the filegroup level and
even at the page level, if needed. The remainder of the database
remains available.
Online indexing—
Concurrent modifications (updates, deletes, and inserts) to the
underlying table or clustered index data and any associated indexes can
now be done during index creation time. For example, while a clustered
index is being rebuilt, you can continue to make updates to the underlying data and perform queries against the data.
Database snapshots—
You can now create a read-only, stable view of a database. A database
snapshot is created without the overhead of creating a complete copy of
the database or having completely redundant storage. A database snapshot
is simply a reference point of the pages used in the database (that is
defined in the system catalog). When pages are updated, a new page chain
is started that contains the data pages changed since the database
snapshot was taken, as illustrated in Figure 2.
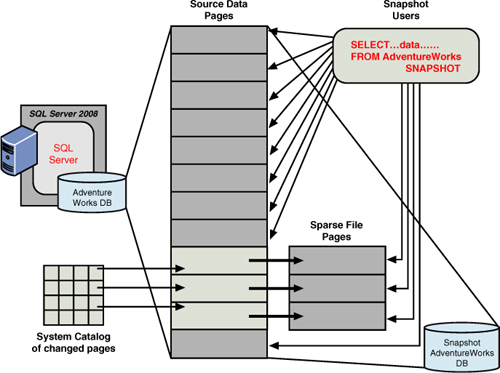
As the
original database diverges from the snapshot, the snapshot gets its own
copy of original pages when they are modified. The snapshot can even be
used to recover an accidental change to a database by simply reapplying
the pages from the snapshot back to the original database.
The
copy-on-write technology used for database mirroring also enables
database snapshots. When a database snapshot is created on a database,
all writes check the system catalog of “changed pages” first; if not
there, the original page is copied (using the copy-on-write technique)
and is put in a place for reference by the database snapshot (because
this snapshot must be kept intact). In this way, the database snapshot
and the original database share the data pages that have not changed.
Data partitioning improvements—
Data partitioning has been enhanced with native table and index
partitioning. It essentially allows you to manage large tables and
indexes at a lower level of granularity. In other words, a table can be
defined to identify distinct partitions (such as by date or by a range
of key values). This approach effectively defines a group of data rows
that are unique to a partition. These partitions can be taken offline, restored, or loaded independently while the rest of the table is available.
Addition of a snapshot isolation level—
This snapshot isolation (SI) level is a database-level capability that
allows users to access the last committed row, using a transactionally
consistent view of the database. This capability provides improved
scalability and availability by not blocking data access of this
previously unavailable data state. This new isolation level essentially
allows data reading requests to see the last committed version of data
rows, even if they are currently being updated as part of a transaction
(for example, they see the rows as they were at the start of the
transaction without being blocked by the writers, and the writers are
not blocked by readers because the readers do not lock the data). This
isolation level is probably best used for databases that are read-mostly
(with few writes/updates) due to the potential overhead in maintaining
this isolation level.
Dedicated administrator connection—
This feature introduces a dedicated administrator connection that
administrators can use to access a running server even if the server is
locked or otherwise unavailable. This capability enables administrators
to troubleshoot problems on a server by executing diagnostic functions
or Transact-SQL statements without having to take down the server.
High Availability from the Windows Server Family Side
To enhance system uptimes,
numerous system architecture enhancements that directly reduce unplanned
downtime, such as improved memory management and driver verification,
were made in Windows 2000, 2003, and 2008 R2. New file protection
capabilities prevent
new software installations from replacing essential system files and
causing failures. In addition, device driver signatures identify drivers
that may destabilize a system. And, perhaps another major step toward
stabilization is the use of virtual servers.
Microsoft Virtual Server 2005
Virtual Server 2005 is a much
more cost-effective virtual machine solution designed on top of Windows
Server 2008 to increase operational efficiency in software testing and
development, application migration, and server consolidation scenarios.
Virtual Server 2005 is designed to increase hardware efficiency and help
boost administrator productivity, and it is a key Microsoft deliverable
toward the Dynamic Systems Initiative (eliminating reboots of servers,
which directly affects downtime!). As shown in Figure 3, the host operating system—Windows Server 2008 in this case—manages the host system (at the bottom of the stack).
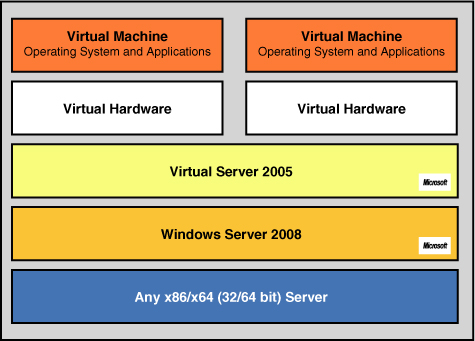
Virtual Server 2005 provides
a Virtual Machine Monitor (VMM) virtualization layer that manages
virtual machines and provides the software infrastructure for hardware
emulation. As you move up the stack, each virtual machine consists of a
set of virtualized devices, the virtual hardware for each virtual
machine.
A guest operating system and
applications run in the virtual machine—unaware, for example, that the
network adapter they interact with through Virtual Server is only a
software simulation of a physical Ethernet device. When a guest
operating system is running, the special-purpose VMM kernel takes
mediated control over the CPU and hardware during virtual machine
operations, creating an isolated environment in which the guest operating system and applications run close to the hardware at the highest possible performance.
Virtual
Server 2005 is a multithreaded application that runs as a system
service, with each virtual machine running in its own thread of
execution; I/O occurs in child threads. Virtual Server derives two core
functions from the host operating system: the underlying host operating
system kernel schedules CPU resources, and the device drivers of the
host operating system provide access to system devices. The Virtual
Server VMM provides the software infrastructure to create virtual
machines, manage instances, and interact with guest operating systems.
An often-discussed example of leveraging Virtual Server 2005
capabilities would be to use it in conjunction with a disaster recovery
implementation.
Virtual Server 2005 and Disaster Recovery
Virtual Server 2005
enables a form of server consolidation for disaster recovery. Rather
than maintaining redundancy with costly physical servers, customers can
use Virtual Server 2005 to back up their mission-critical functionality
in a cost-effective way by means of virtual machines. The Virtual
Machine Monitor (VMM) and Virtual Hard Disk (VHD) technologies in
Virtual Server 2005, coupled with the comprehensive COM API, can be used
to create similar failover functionality as standard, hardware-driven
disaster recovery solutions. Customers can then use the Virtual Server
COM API to script periodic duplication of physical hard disks containing
vital business applications to virtual machine VHDs. Additional scripts
can switch to the virtual machine backup in the event of catastrophic
failure. In this way, a failing device can be taken offline to
troubleshoot, or the application or database can be moved to another
physical or virtual machine. Moreover, because VHDs are a core Virtual
Server technology, they can be used as a disaster recovery agent,
wherein business functionality and data can be easily archived,
duplicated, or moved to other physical machines.